Как работает TuchaKube — первая украинская DevOps/Hosting-платформа
- Главная
- Блог
- Облачные сервисы
- Как работает TuchaKube — первая украинская DevOps/Hosting-платформа
Продолжаем знакомиться с мощными возможностями сервиса TuchaKube и особенностями его работы. В предыдущей статье мы писали о том, как возникла идея создать платформу для автоматизации CI/CD-процессов, хостинга приложений и данных в облаке контейнеров, а также из чего она состоит и какие задачи решает. Теперь рассказываем и показываем, как именно работает инновационное решение.
Процесс автоматизации CI/CD-процессов осуществляется по определенным наработанным нами шаблонам, которые являются гибкими и могут настраиваться под потребности конкретного заказчика.
Шаг 1. Разработчик сначала делает commit в локальный git-репозиторий, а затем — push в удаленный git-репозиторий в отдельном GitLab, который предоставляется клиенту. Это действие и является триггером для начала процесса сборки, если не заданы другие параметры. Если же у разработчика нет прав деплоить в текущую ветку, то разработчик осуществляет merge request, который обрабатывается тем, у кого есть такие права.
После того как изменения, внесенные заказчиком, попадают в определенную ветку кода, которая требует выполнения автоматических процессов, происходит анализ этого кода и внесенных обновлений.
Шаг 2. Затем автоматически создаются контейнеры на базе наших Docker-файлов. Поскольку у нас уже есть определенная накопленная библиотека стандартных Docker-файлов, для использования в работе они требуют наименьшей доработки.
Создание контейнеров обусловлено непосредственным функционированием платформы: она требует, чтобы все приложения и компоненты программного обеспечения заказчика выполнялись именно в контейнерах.
Контейнер пушится в какой-нибудь репозиторий — локальный (например, репозиторий контейнеров у предоставленного клиенту GitLab) или удаленный (например, Docker Hub или любой другой docker registry).
Шаг 3. После этого производится тестирование. Это означает, что система в одном из «закоулков» облака запускает один или несколько контейнеров и выполняет с ними то, что прописано разработчиком в программе автоматического тестирования. Отметим, что алгоритмы составляются исключительно заказчиками (собственноручно или при помощи QA-инженеров).
Шаг 4. Далее происходит процесс удаления лишних данных. В отдельных случаях происходит перекомпиляция. Также после этого иногда еще раз производится тестирование.
Шаг 5. Следующий шаг — доставка новой версии непосредственно в staging-среду. Этот процесс происходит так: сначала запускаются контейнеры с новой версией. Затем, когда система убедилась в том, что контейнеры заработали должным образом (обычно выполняются так называемые readiness probes, которые позволяют определить, корректно ли Pod отвечает на запросы), она переключает трафик на новые контейнеры, а старые постепенно выключает.
Таким образом, происходит автоматическое обновление в staging-среде
1. Заказчик делает определенный коммит.
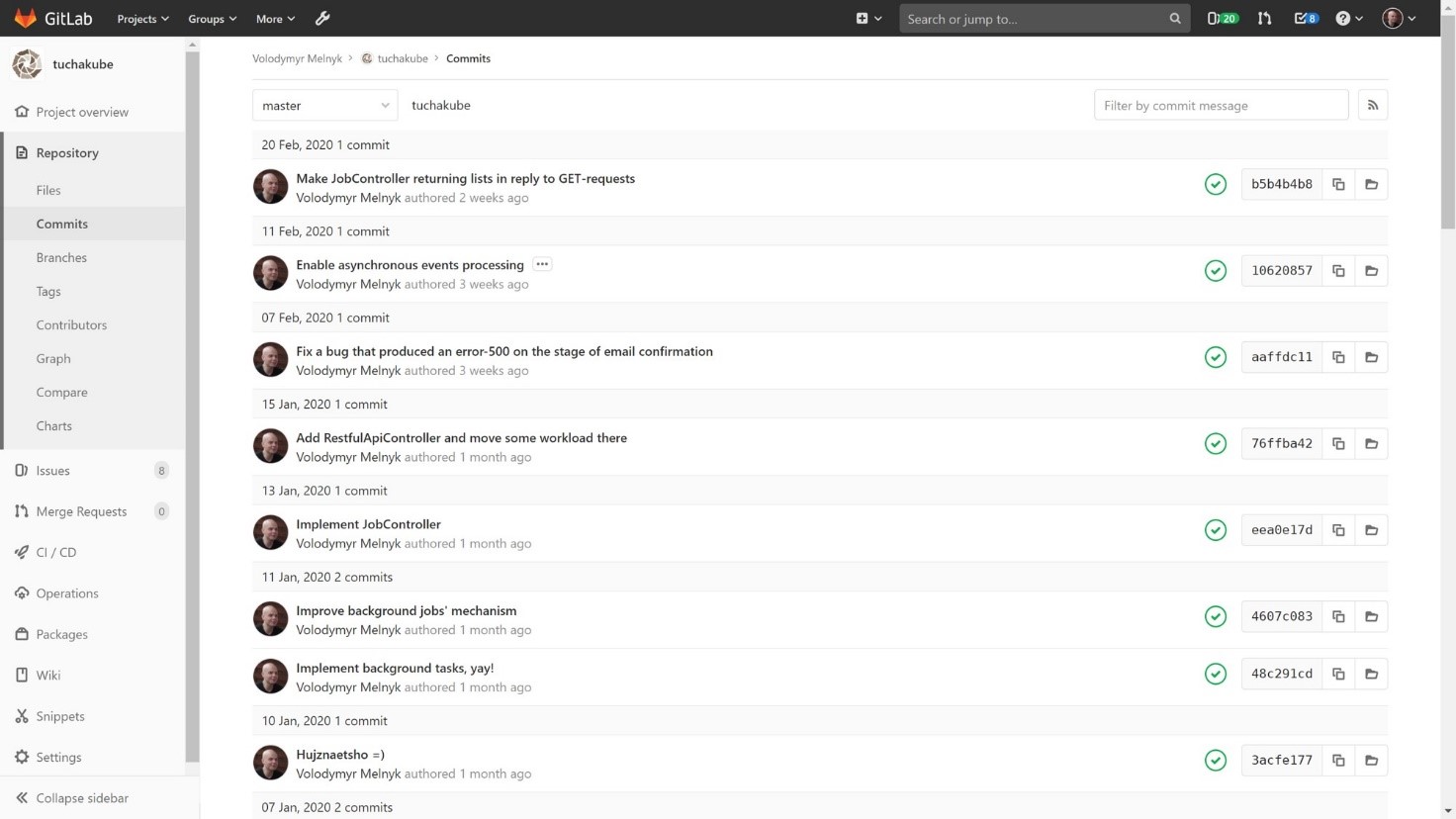
2. Коммиту присваивается идентификатор. В дальнейшем он будет использоваться для отслеживания всех действий и изменений, которые будут происходить с этим процессом. Тестирование также производится с указанием этого уникального идентификатора.
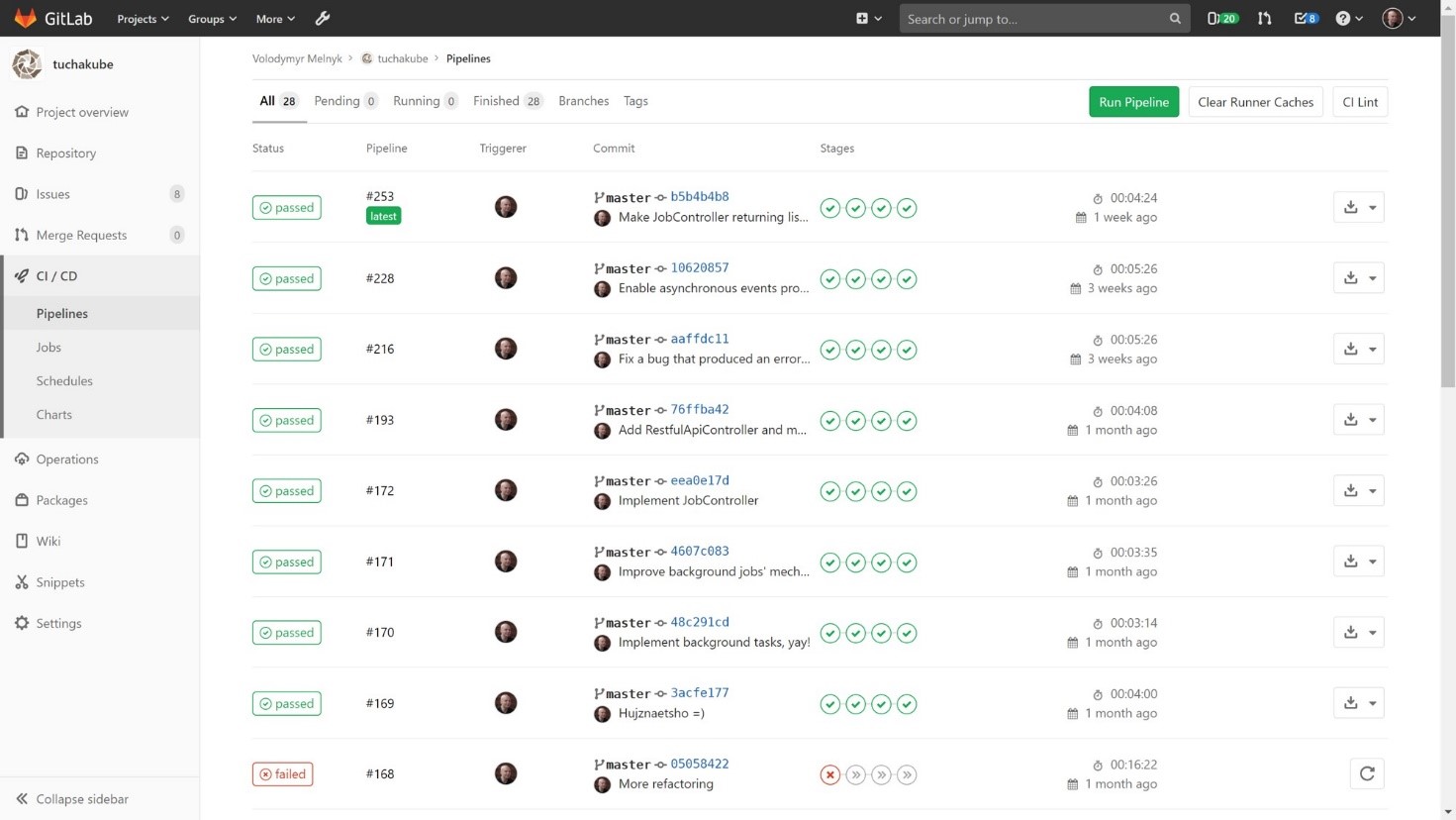
Иными словами, как только заказчик сделает коммит, соответствующий определенным заданным критериям (они определяются DevOps-инженером в конфигурационном файле CI/CD-процессов конкретного проекта), сразу будут автоматически выполняться действия в несколько этапов. Эти этапы задаются нами на базе пожеланий заказчика:
1) Сборка (компиляция) проекта.
Проект компилируется таким образом, чтобы сначала можно было посмотреть, есть ли определенные закешированные из предыдущей компиляции библиотеки, которые могут нам пригодиться, поскольку компиляция (как и все дальнейшие процессы) происходят в отдельных контейнерах. Поскольку контейнер является «чистой» системой, внутри которой еще ничего нет, при выполнении каждого шага он берет из нашего локального S3-совместимого хранилища те данные, которые сохранились с предварительных отработок. Этот процесс необходим потому, что проекту, который будет компилироваться, необходимо собрать большое количество библиотек и распределить их. Таким образом, рабочие данные и библиотеки хранятся в S3-совместимом хранилище для того, чтобы затем можно было их использовать.
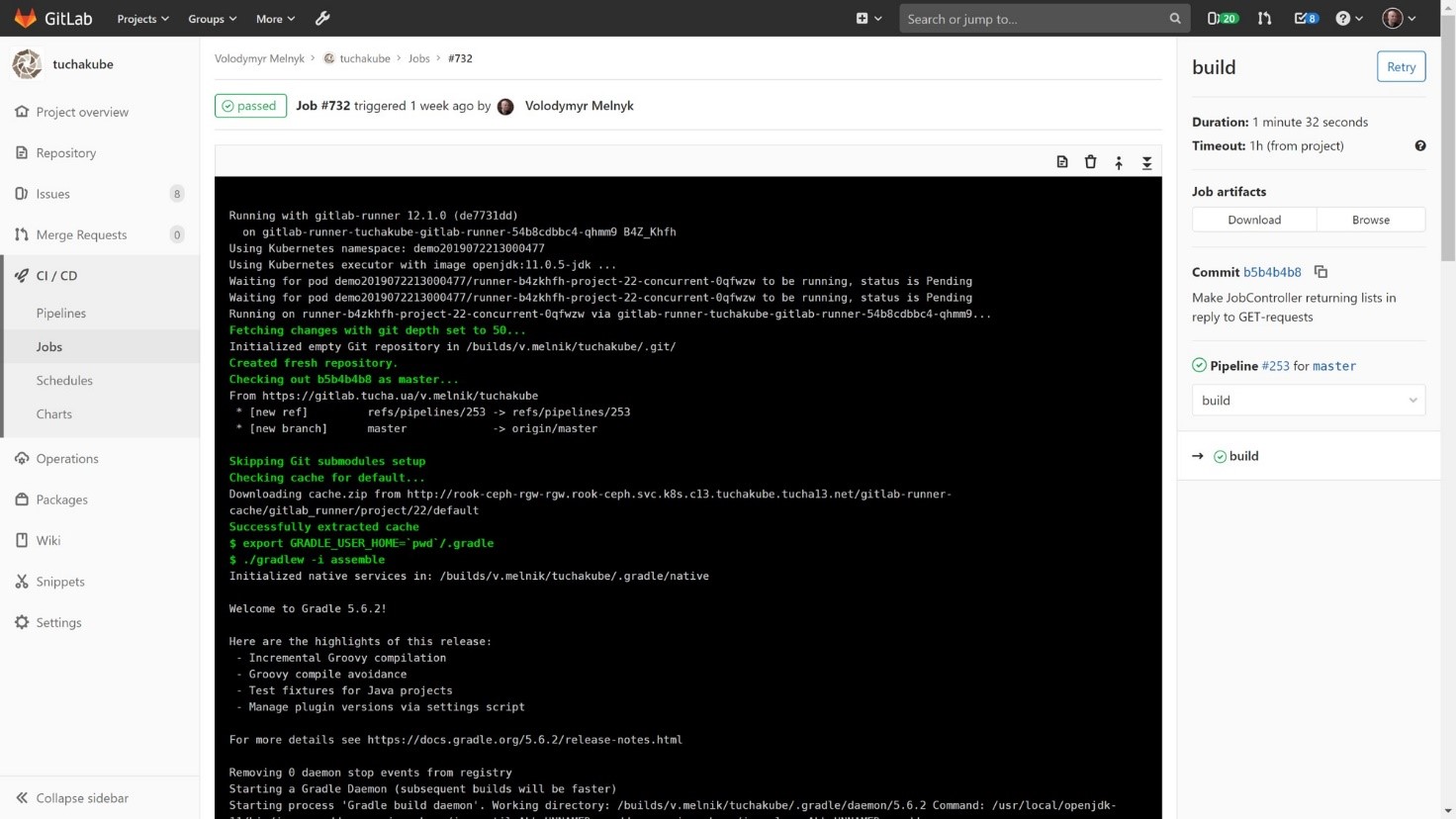
Кроме этого, также сохраняются артефакты (любые файлы, которые разработчик хочет сохранить после сборки), которые потом мы можем использовать для работы.
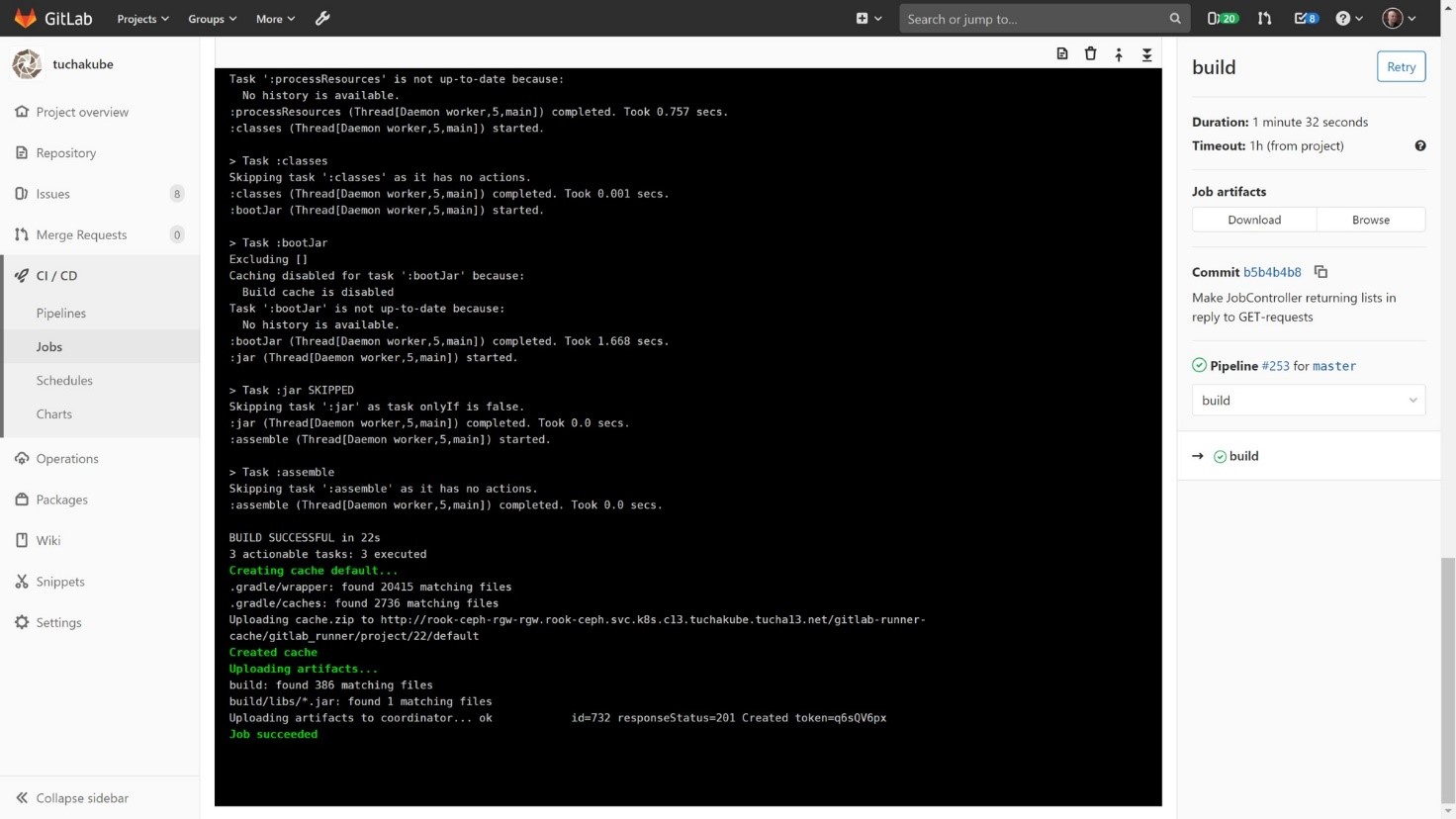
В хранилище артефактов есть возможность заглянуть в артефакты для каждого отдельного билда и посмотреть, что лежит в хранилище артефактов для каждого отдельного идентификатора. Каждый коммит содержит свой уникальный идентификатор.
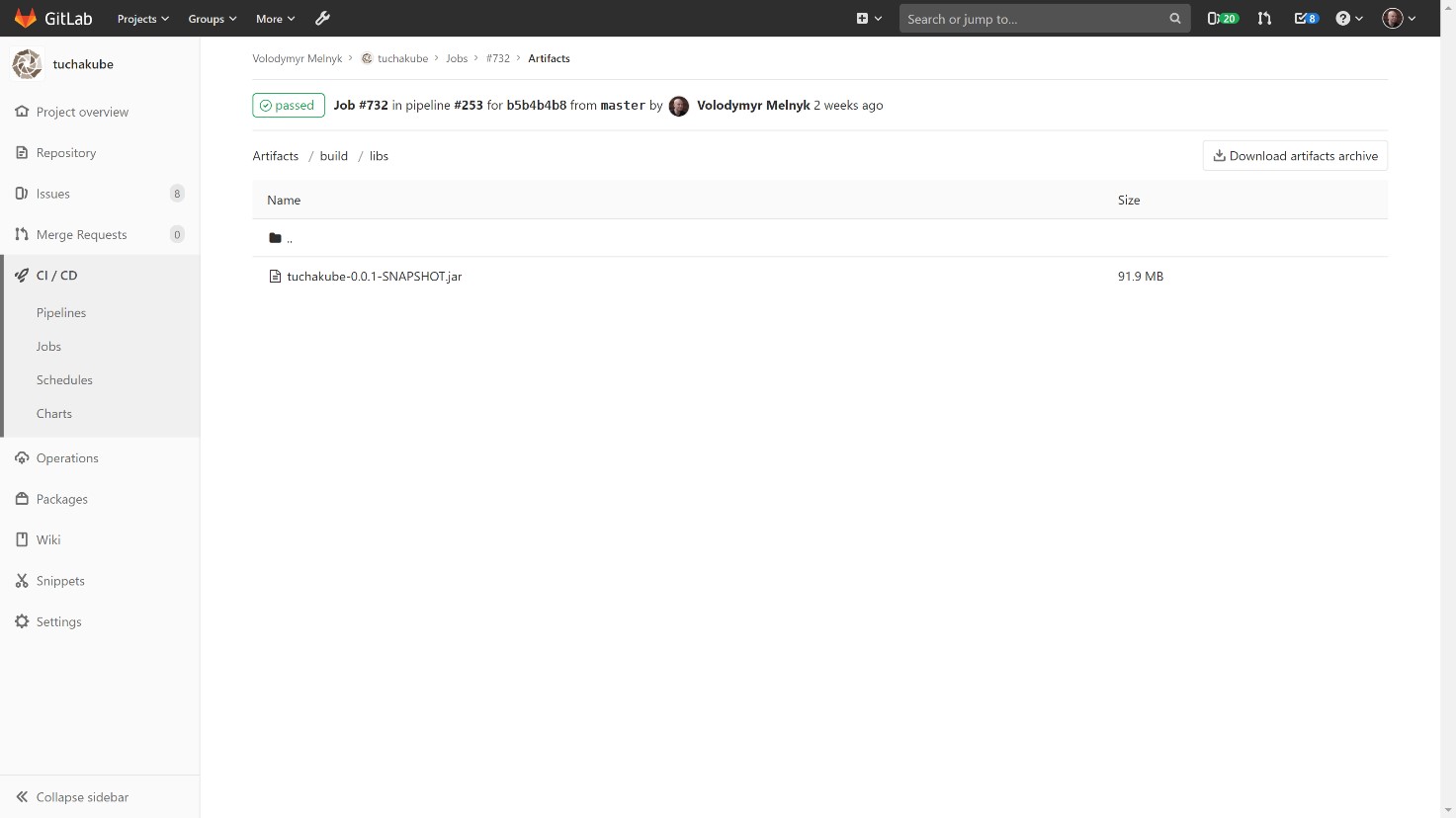
2) Тестирование.
Этот процесс также происходит с указанием уникального идентификатора. Точно так же происходит восстановление артефактов (важно) и восстановление рабочих данных (не всегда является необходимым).
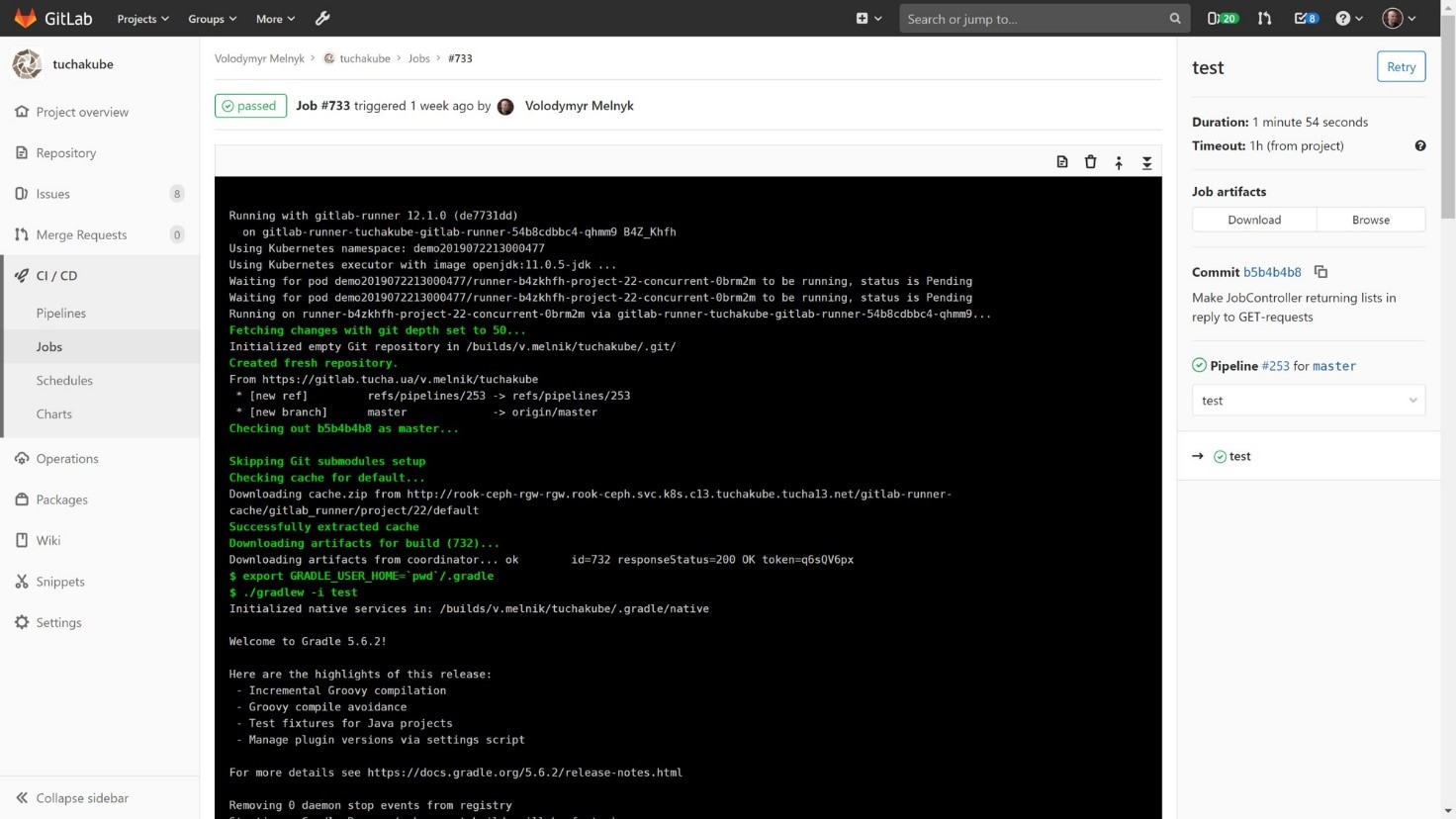
После того как произошло автоматическое тестирование, наступает время для повторного сохранения рабочих данных, если это необходимо. Отметим, что после тестирования артефакты обычно не меняются.
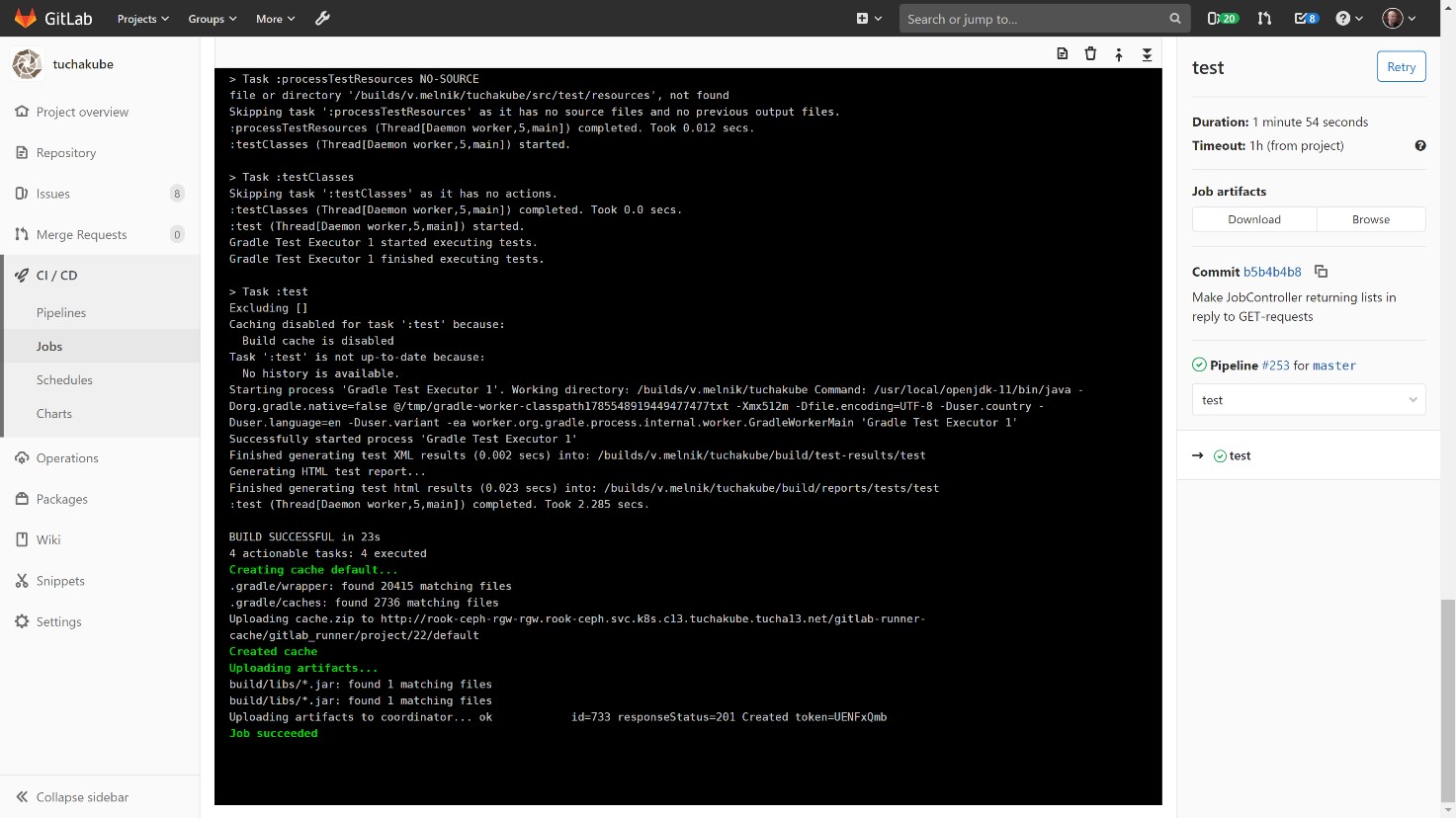
3) Контейнеризация.
С тем же идентификатором мы собираем контейнер на базе Docker-файла, который создали для компонента этого проекта.
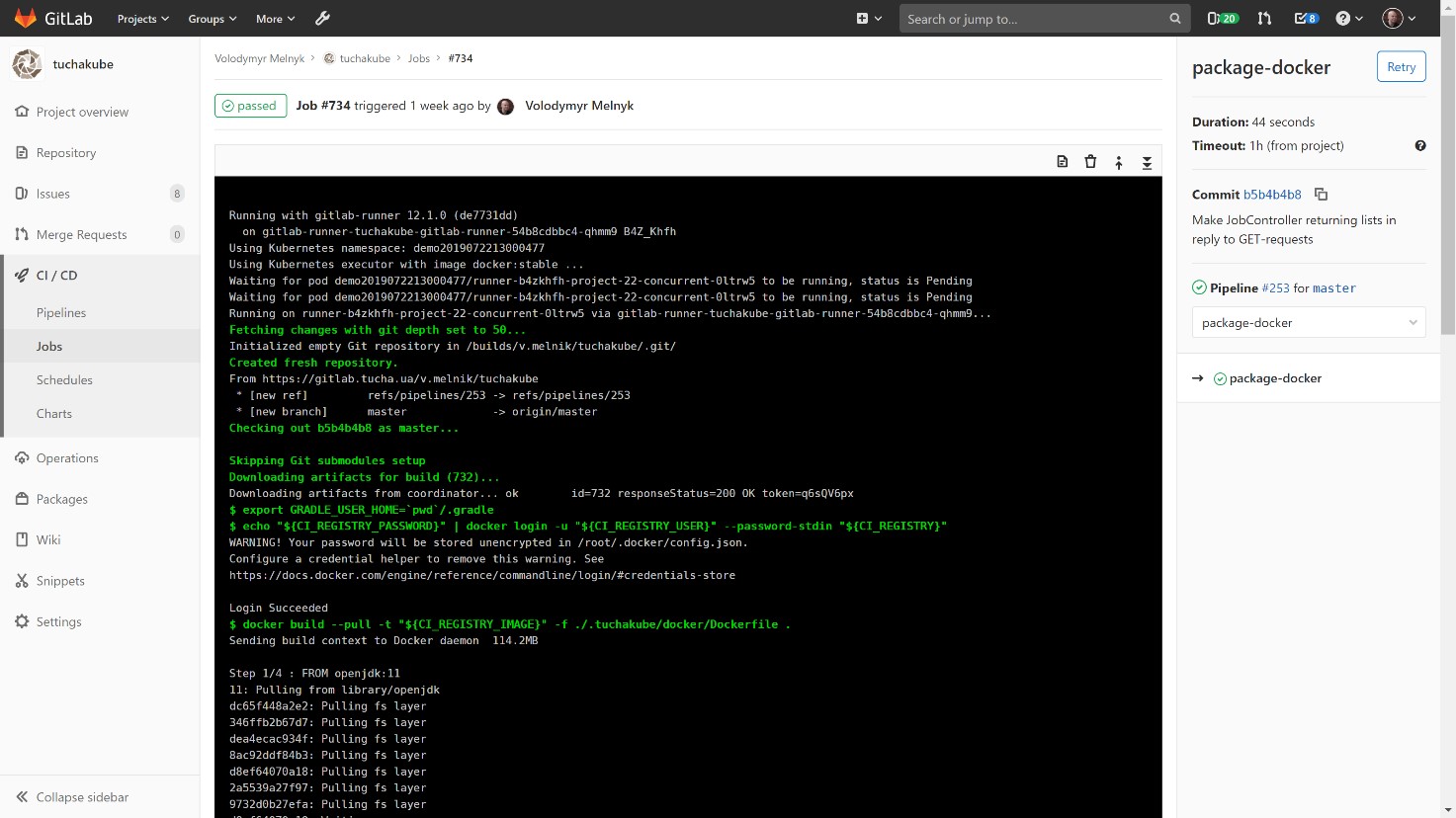
Собранный Docker-контейнер хранится в нашем локальном хранилище, Docker Registry, который тоже принадлежит клиенту.
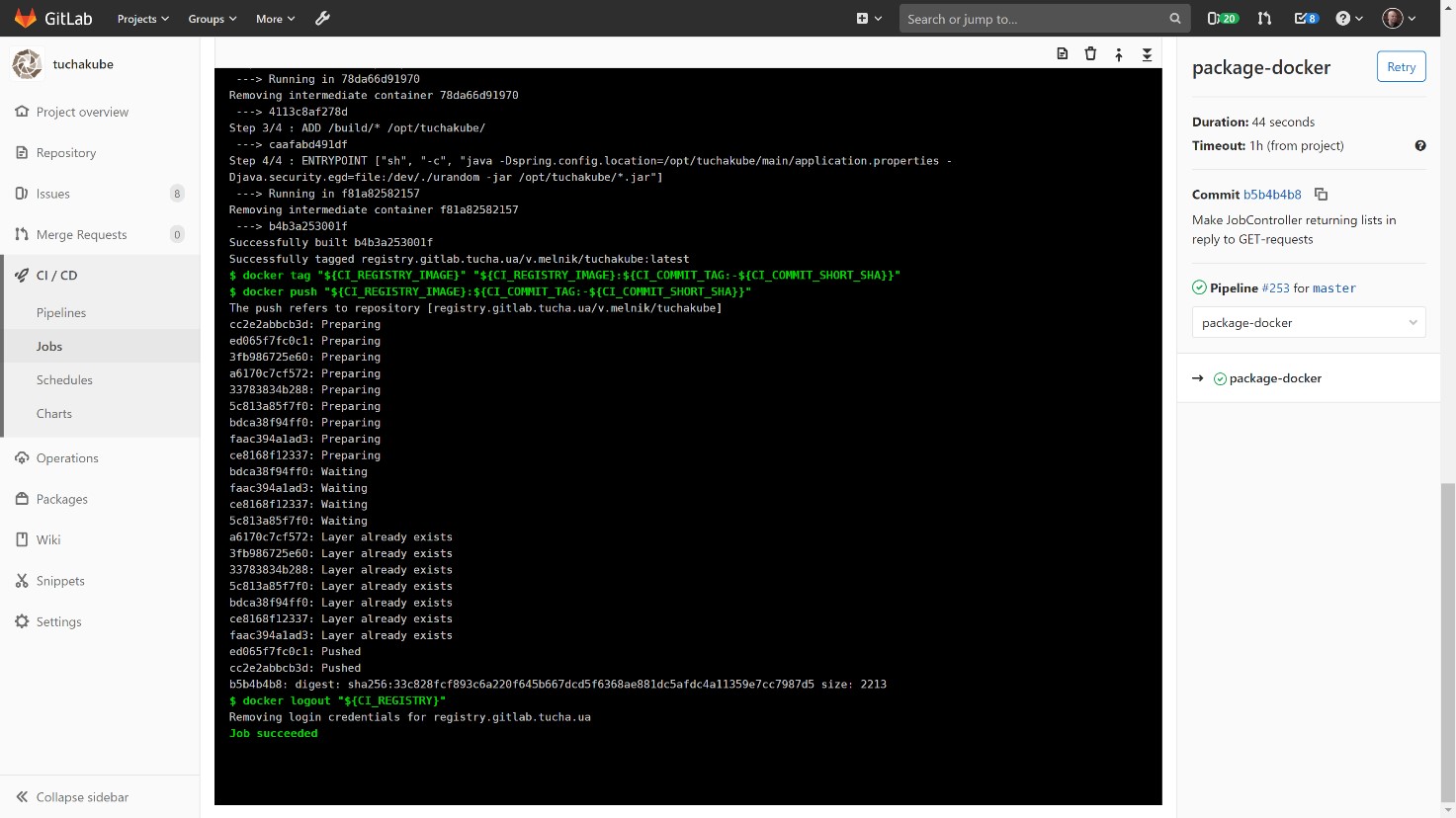
Заказчик может заглянуть в него и посмотреть, какие контейнеры существуют, какие версии у них есть и что содержится внутри, а также удалить некоторые данные, если это нужно. Также можно задавать алгоритмы автоматического удаления (обычно данные хранятся в течение 14 суток).
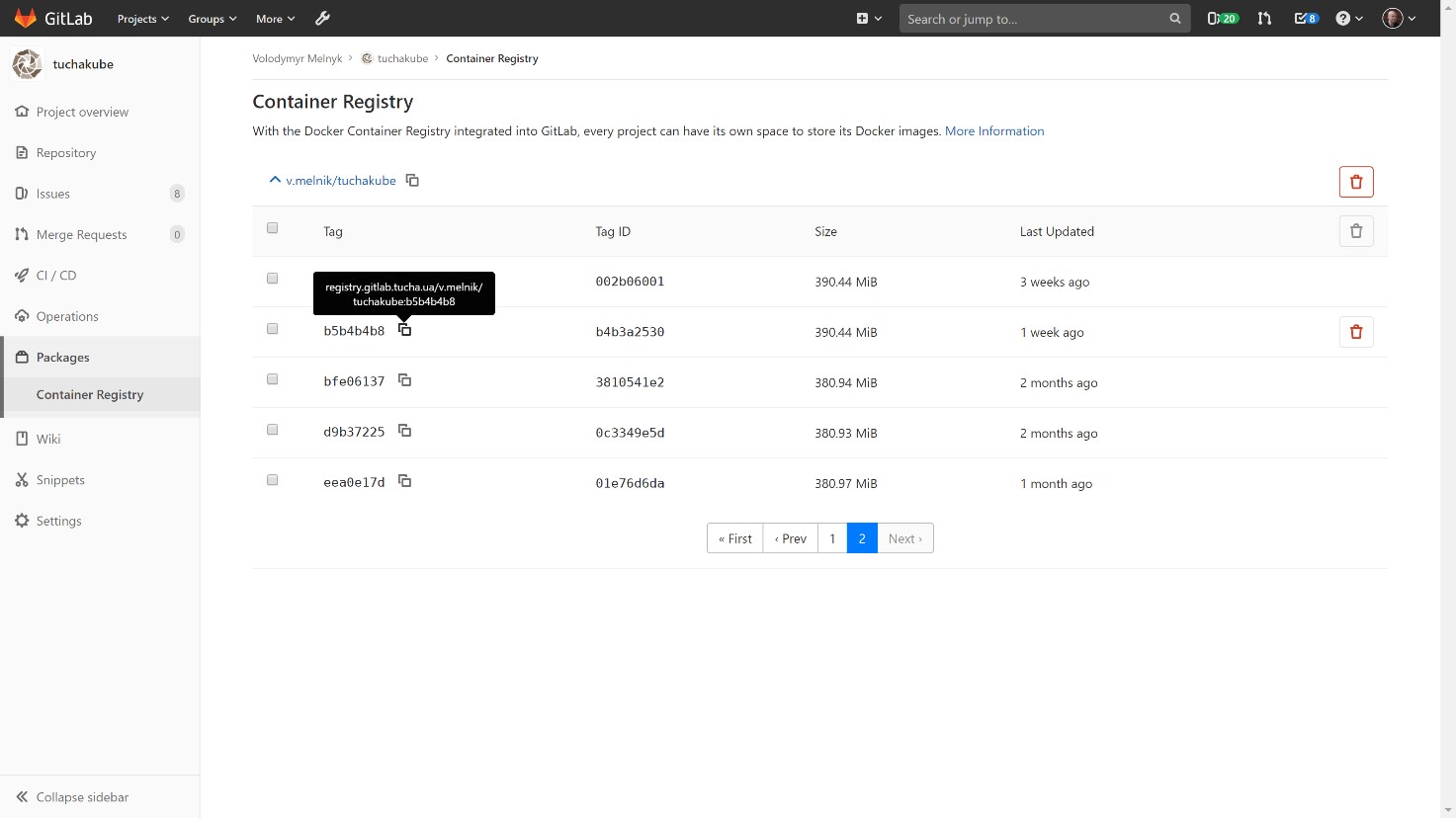
4) Доставка контейнера в staging-среду.
После того как контейнер собран, происходит доставка его в staging-среду. Рекомендуем все же сначала выполнить эти действия в staging-среде, для того чтобы по отдельному адресу лично убедиться, как работает новая версия.
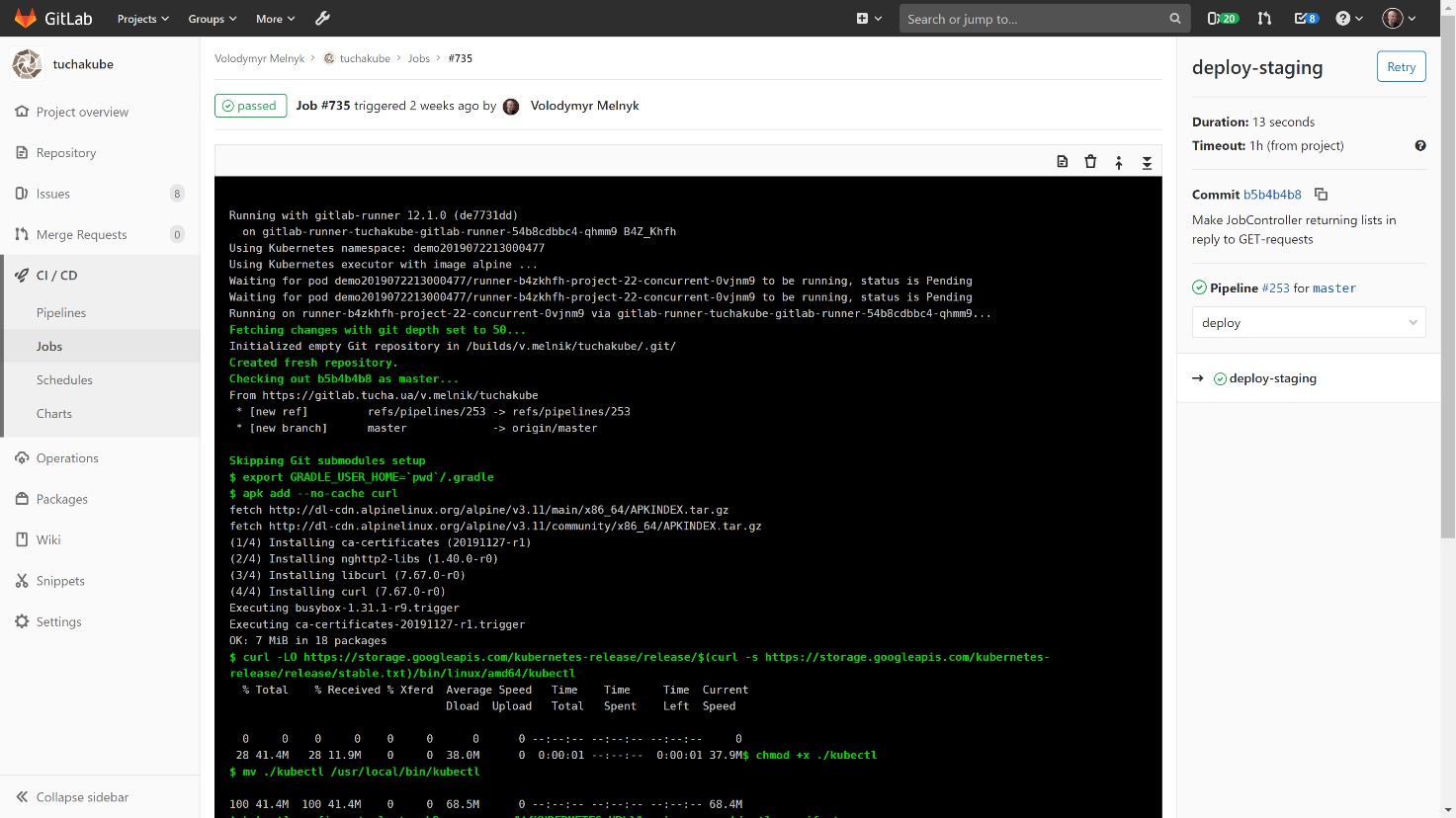
Далее обычно создается деплоймент манифест для Kubernetes, который тоже содержит в себе идентификатор этого коммита (в то же время это и идентификатор Docker-образа, который затем будет использоваться).
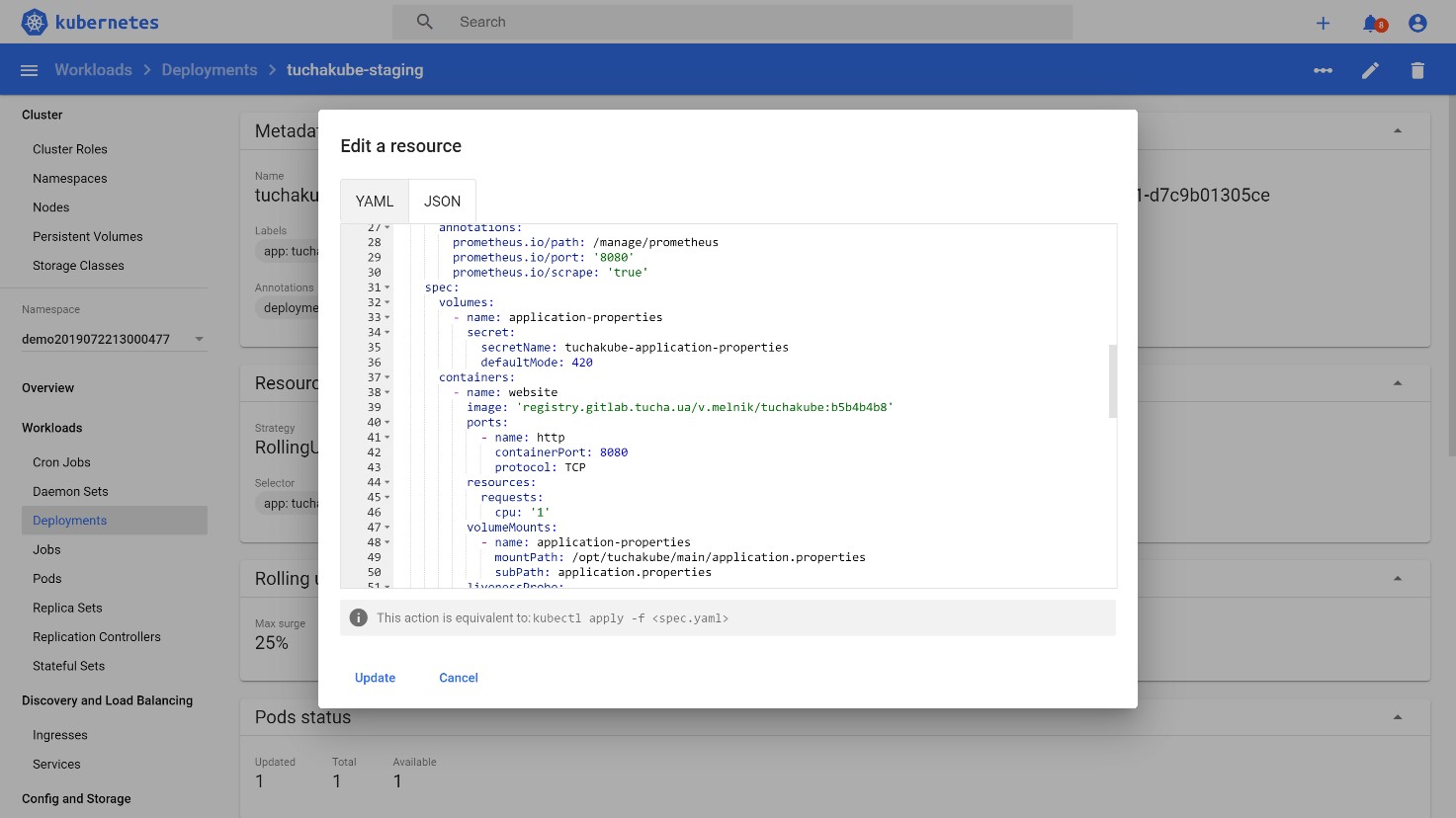
То есть автоматически создается манифест, который содержит в себе этот идентификатор. Реквизиты доступа, необходимые для авторизации в хранилище, обычно хранятся внутри Kubernetes-кластера в виде специальных сущностей под названием «secret».
Далее все это деплоится в staging-среду как отдельная версия того же деплоймента, но с обновленными контейнерами внутри Pod.
Сначала производится запуск Pod-ов с контейнерами в нужном количестве в Kubernetes-кластере, но трафик на них не поставляется. Трафик начинает поступать к ним тогда, когда Kubernetes убедится в том, что этот трафик будет обрабатываться корректно. То есть он производит тестирование: например, проверяет доступность приложения внутри по порту, на котором он работает. Если реакция будет такой, которая ожидается, Kubernetes начинает переключать на него трафик.
5) Обновление в production-среде.
Этот этап происходит после того, как мы убедились, что в staging-среде все работает должным образом, а QA-команда обработала свои алгоритмы по мануальному тестированию и удовлетворилась результатами.
При обновлении в production-среде происходит то же действие, что и во время доставки контейнера в staging-среду, — выполняется merge в ветку, которая является мастер-веткой или одной из них. Есть только одна небольшая разница: выполнение финального этапа производится в ручном режиме. То есть после того как разработчик или другое уполномоченное лицо убедится, что все хорошо работает в staging-среде, он просто запускает этот этап нажатием кнопки Play в пайплайнах. То есть заключительное действие производится вручную, а не автоматически.
Для возможности осуществления мониторинга и горизонтального масштабирования нам нужно было обеспечить сбор разнообразных данных: как от приложения, который разрабатывает заказчик, так и от системы Kubernetes. Зачастую через Metrics-сервер это попадает в Prometheus, и тот уже хранит информацию обо всех метриках. В дальнейшем пользователь может просматривать их с помощью Grafana.
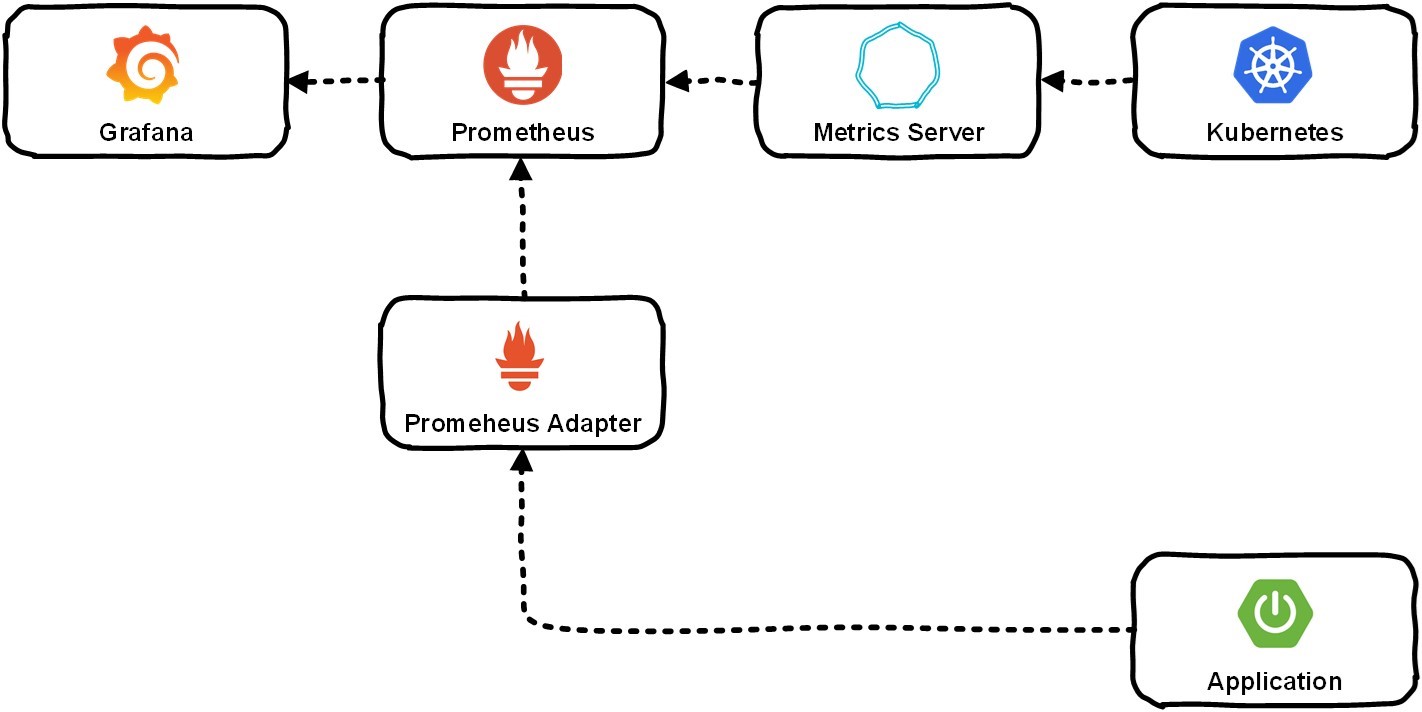
Рассмотрим на примере конкретного приложения.
Ситуация 1. Запросы не поступают.
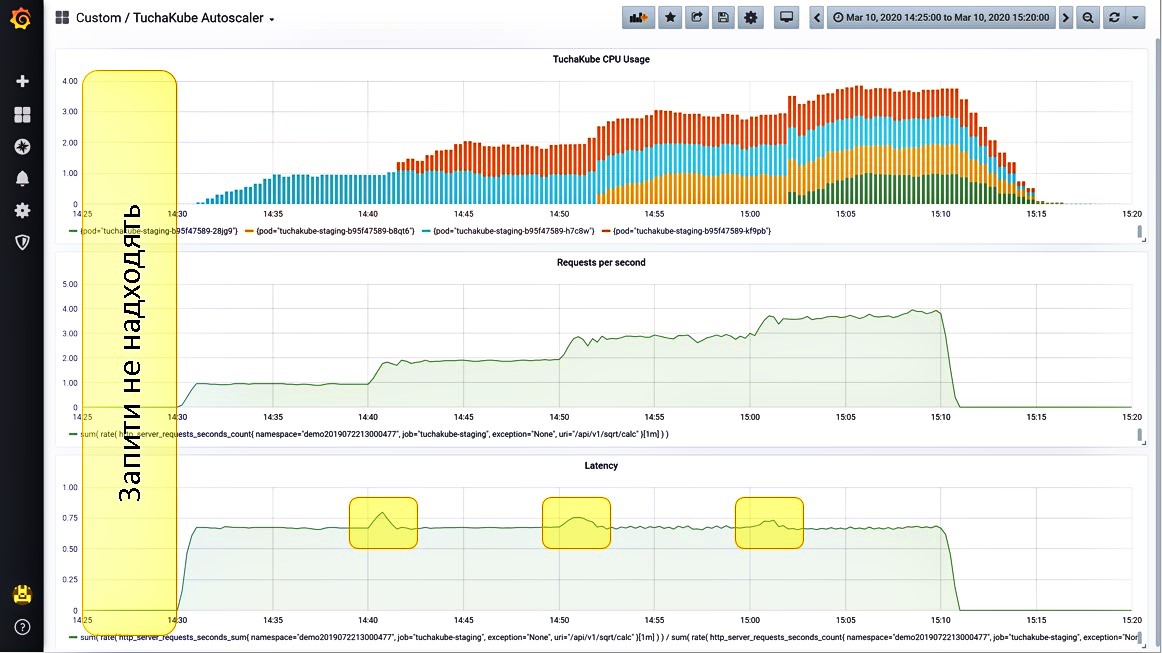
Мы вывели на Grafana 3 метрики, которые мониторятся в платформе TuchaKube:
- загрузка центрального процессора (голубые столбики);
- количество запросов в секунду, поступающих на этот сервис (желтые столбики);
- задержка, которая возникает при обработке одного запроса (зеленые столбики).
Ситуация 2. Даем один поток запросов.
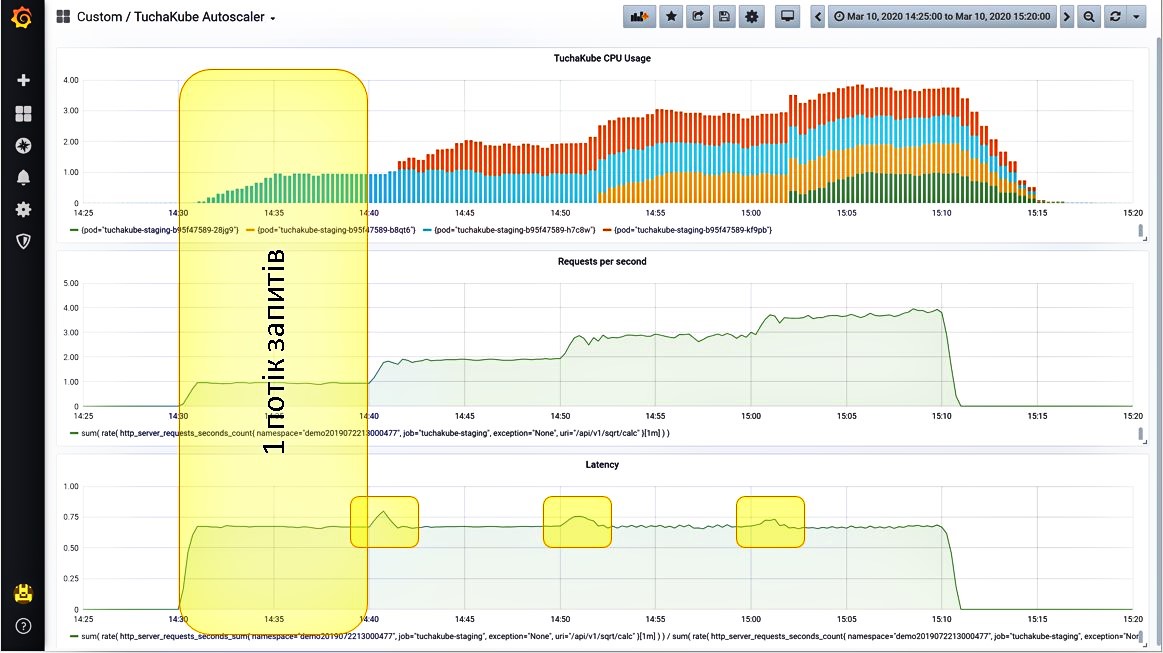
Нагрузка начинает расти. Поскольку этот показатель измеряется 1 раз в 5 минут, на самом деле он растет не так постепенно, как отображает график, а немного быстрее.
Итак, после того как увеличилось количество запросов в секунду, приложение начало прорабатывать эти запросы. Встроенный сервер метрик показывает определенное количество времени, необходимое для обработки одного запроса.
Ситуация 3. Даем еще один поток запросов.
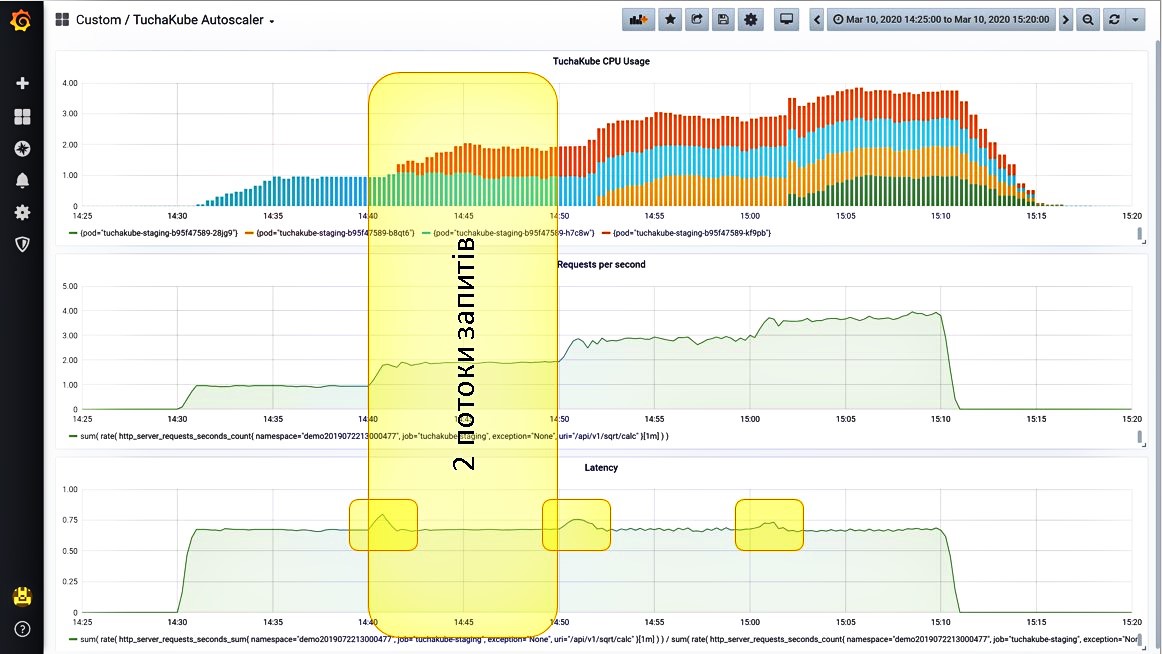
Нагрузка начинает расти, и система это отслеживает. Также она видит, что количество запросов в секунду увеличилось. Теперь система запускает второй контейнер (красные столбики на графике).
Рассмотрим этот процесс подробнее. Сначала произошло вот что: задержка для отработки одного запроса немного выросла, но это сразу было сбалансировано благодаря еще одному контейнеру, который запустился.
Ситуация 4. Даем большее количество запросов.
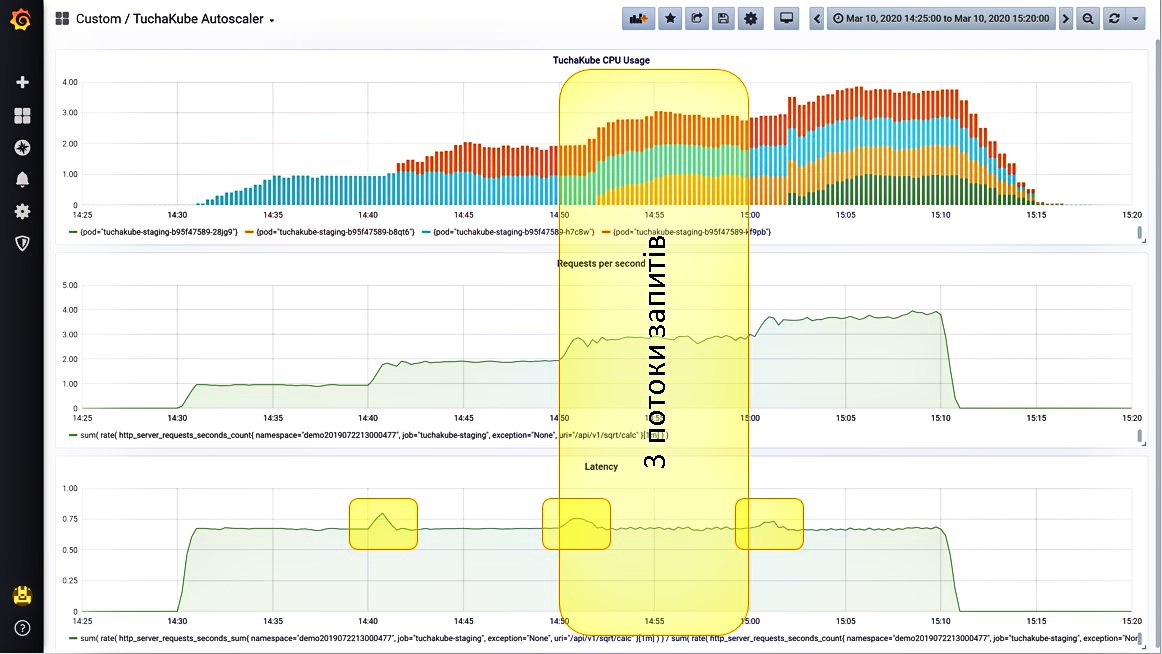
Продолжаем добавлять третий поток запросов. Система наблюдает, что нагрузка растет, и запускает еще один контейнер. Возросло количество запросов в секунду. При этом снова на небольшое время возросла задержка, но затем ее показатель снова снизился.
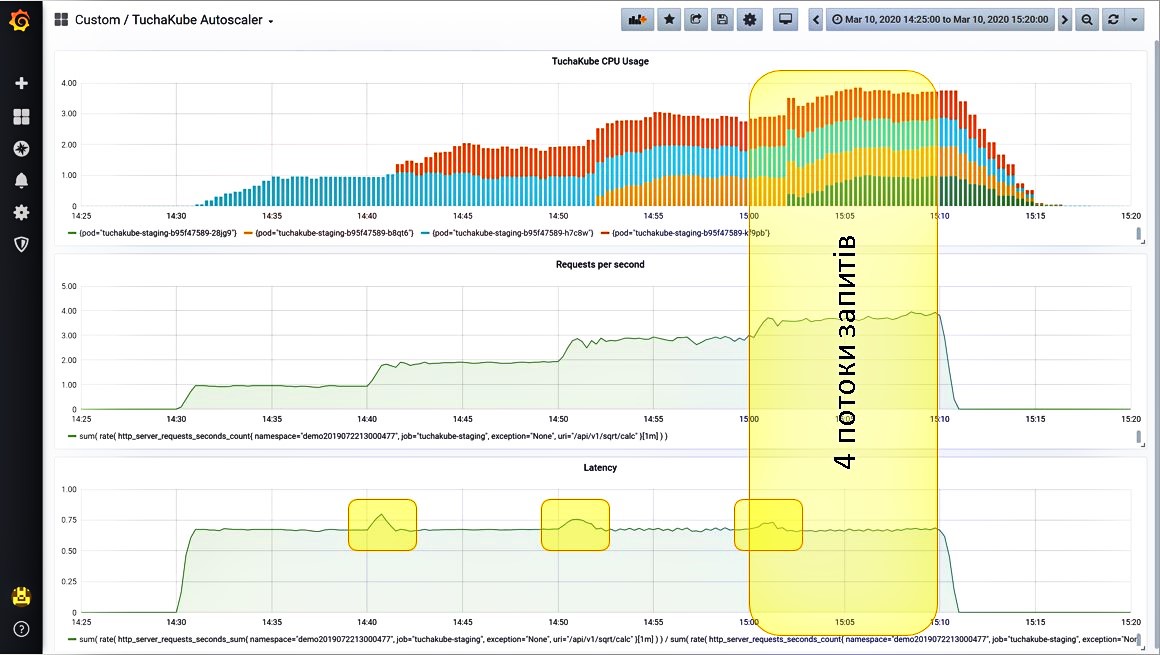
Четвертый поток запросов система «переживает» так же замечательно, поскольку при этом снова запустился контейнер. Сначала показатели задержки немного выросли, но потом они снова дошли до нужного нам уровня.
Ситуация 5. Выключаем все запросы.
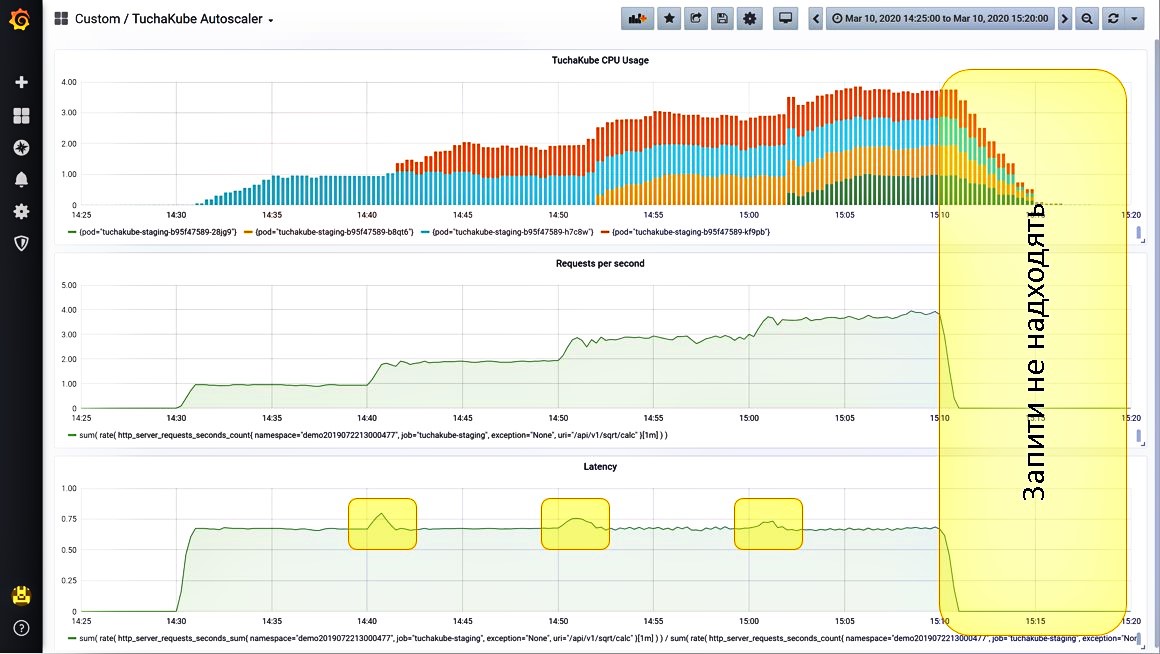
После того как мы выключили все запросы (это задается отдельными настройками), видим, что нагрузка упала. Далее лишние контейнеры удаляются из Kubernetes для того, чтобы не создавалась дополнительная нагрузка для клиентов и не происходила тарификация за ресурсы, которые клиенту не нужны.
Ситуация 6. А если включить сразу все 4 потока запросов?
Такую процедуру тоже можно выполнить. Платформа обработает их точно так же: сначала немного возрастут показатели нагрузки, но система сразу заметит это и быстро запустит все 4 контейнера.
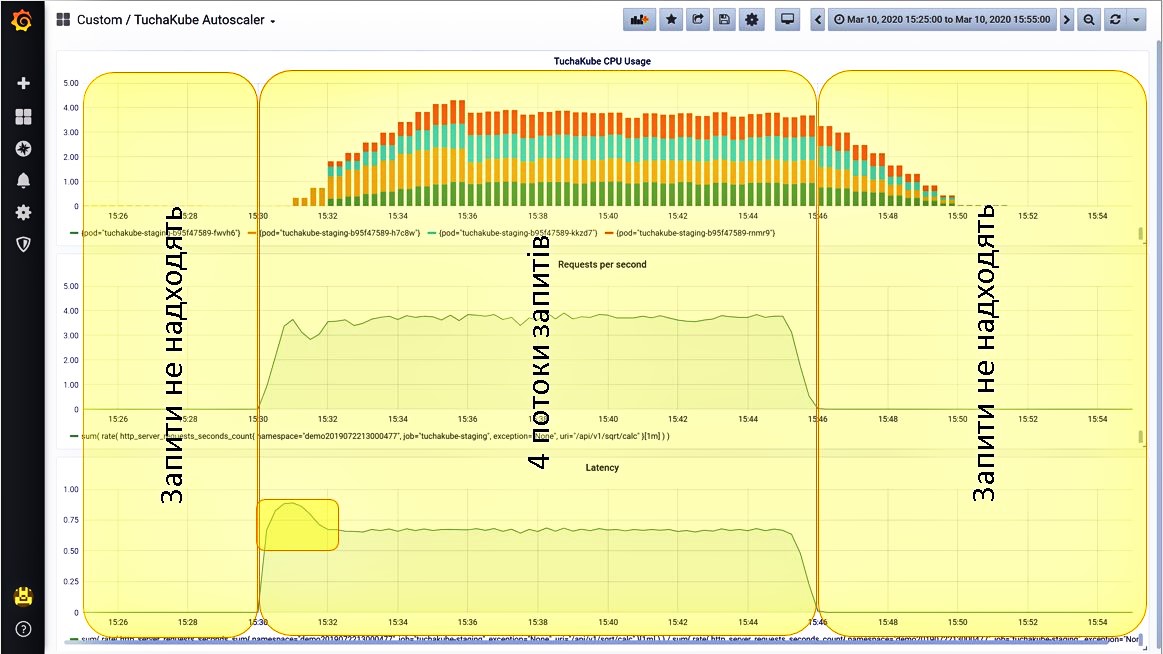
Вот так происходит горизонтальное масштабирование, которое можно мониторить.
В основном базы данных у нас являются отдельными кластерами, которые работают вне Kubernetes на отдельных серверах, — виртуальных или физических. Но между ними и приложением есть кольцо из прокси-контейнеров, которые выполняют роль балансировщиков запросов между приложением заказчика и кластером баз данных. Базы данных могут быть разными.
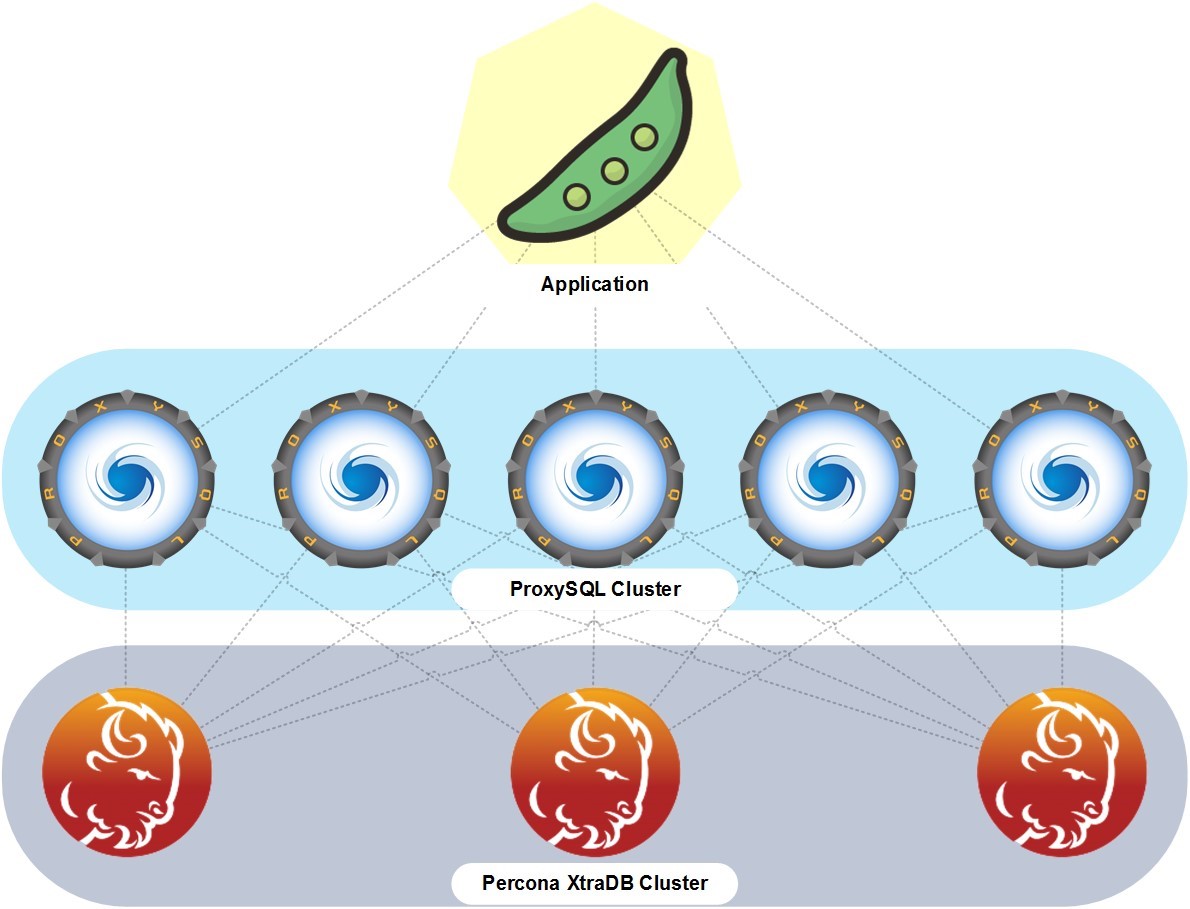
Заказчик может управлять базами данных, например, с помощью phpMyAdmin, если речь идет о MySQL-совместимых базах данных, которые мы тоже для него устанавливаем и настраиваем. Обычно мы создаем кластер серверов баз данных для обеспечения бесперебойности и отказоустойчивости.
Надежная техническая поддержка — важный компонент платформы TuchaKube. Наша команда специалистов работает 24×7 и прилагает все усилия, чтобы каждый клиент получал качественный сервис и квалифицированную помощь в решении облачных задач.
Несмотря на то, что служба поддержки Tucha работает по достаточно жесткому регламенту, главное для нас — полное удовлетворение клиента услугами, которые он заказывает. Поэтому мы внимательно и ответственно относимся к задачам заказчиков и действительно заинтересованы в их быстром и добросовестном решении. Это одно из главных свойств нашей службы технической поддержки, которая позволяет приносить клиентам максимум пользы от сотрудничества.
Платформа TuchaKube — инновационное решение, которое значительно упрощает процессы разработки программных продуктов, помогает строить высоконагруженные ИТ-системы и автоматизировать CI/CD-процессы.
Уникальность сервиса заключается в сочетании сразу многих компонентов и множестве мощных возможностей: горизонтальное масштабирование, мониторинг, сбор и хранение статистических данных, кластеризация и другие. А главное преимущество — это лучшая поддержка со стороны опытных DevOps-инженеров Tucha.
Если у вас есть веб-проект, который уже работает и для которого были бы полезны возможности платформы, приглашаем к ее тестированию! А если вы хотите узнать больше о сервисе или у вас есть реальные задачи для нас, звоните по телефону +380 44 583-5-583 или пишите по электронному адресу support@tucha.ua. Мы всегда на связи, готовы ответить на ваши вопросы и подобрать наилучшее облачное решение. Обращайтесь!




